
The problem
In our crowd-sourcing smartphone application Schnëssen we are collecting tons of audio recordings for translations of sentences into Luxembourgish. Intended as a variation linguistic project, the rationale behind this is to elicit pronunciation or lexical variants for ongoing languages changes in Luxembourgish. Participants are asked to translate short sentences like:
Die Amsel fliegt hoch in der Luft. ‚The blackbird is flying high in the sky.‘
These stimuli sentences are constructed to elicit certain know variants through the translation into Luxembourgish, e.g. German ‚Amsel‘ can be rendered in Luxembourgish as ‚Märel‘, ‚Kueb‘, ‚Vull‘ or even ‚Amsel‘. Most of the other words in the sentence are also intended to elicit certain variants.
German |
Die |
Amsel |
fliegt |
hoch |
in der |
Luft. |
|---|---|---|---|---|---|---|
Luxembourgish |
D‘ |
Märel |
flitt |
héich |
an der |
Luucht. |
_ |
D‘ |
Amsel |
fléit |
hiich |
an der |
Loft |
_ |
De |
Kueb |
flikt |
hi |
an der |
Lut. |
_ |
… |
… |
… |
… |
… |
… |
In our project, we have constructed around 400 of these stimuli sentences, which have been translated and recorded by between 200 to 1400 speakers. This amounts to a total of 270,000 audio recordings. In order to understand the linguistic variation in Luxembourgish, all these recordings have to be manually annotated, i.e. listened to, which is extremely time-consuming.
Are they any options to support and facilitate this manual annotation and develop a (semi-)automatic annotation system for linguistic, i.e. acoustic variants? As a high-quality system for speech recognition does not yet exist for Luxembourgish, we will have to rely on other techniques.
Fortunately, a system for the forced phonetic alignment of Luxembourgish has been developed recently in the context of the BASWebServices a the University of Munich. The MAUS system takes the orthographical text and the corresponding audio file as input to compute the segmentation of the words and phonetic segments in the audio signal. Thus, if the text spoken in an audio recording is known, the system is able to detect words and segments in the audio. In addition, MAUS also allows indicating potential pronunciation variants for all words in the orthographical text. As for the problem at hand here, most of the potential variants that could occur in these tons of audio recordings are known, MAUS, then, could also be applied for variant detection.
Towards a solution
The solution proposed here has been implemented in R using mainly the package emuR, which provides a wrapper to access all the MAUS tools from within R.
The forced phonetic alignment needs as its input, next to the audio file, the orthographic text as well as a canonical phonetic transcription.
LBD:
ORT: 1 märel
ORT: 2 flitt
ORT: 3 héich
ORT: 4 an
ORT: 5 der
ORT: 6 luucht
KAN: 0 d̥
KAN: 1 m ɛː ʀ ə l
KAN: 2 f l i t
KAN: 3 h ɜɪ ɕ
KAN: 4 ɑ n
KAN: 5 d ɐ
KAN: 6 l uː x t
ORT: 0 d'
The above-mentioned sentence has been recorded for 1240 speakers. In the first step, these data have to be imported into an emuDB database.
library(emuR)
### create new emuDB
# create new db from pairs of wav and a canonical phonetic transcription files
convert_BPFCollection(dbName = recording,
sourceDir = file.path(db_dir, recording),
targetDir = file.path(db_dir, recording),
extractLevels = c("KAN", "ORT"),
refLevel = "ORT",
unifyLevels = c("KAN"),
verbose = F)
After loading the database, the forced alignment can be carried out with the function runBASwebservice_maus.
db <- load_emuDB(paste0(file.path(db_dir, recording), "/", recording, "_emuDB"))
runBASwebservice_maus(db,
canoAttributeDefinitionName = "KAN",
language = "ltz-LU",
params =list(INSYMBOL=c("ipa"), OUTSYMBOL=c("ipa"),
RULESET=httr::upload_file("rules.nrul")),
patience = 3,
resume = T,
verbose = T)
Important parameters include the language setting ltz-LU for Luxembourgish and the type of phonetic transcriptions used for input and output, here IPA. Furthermore, a ruleset is used for the detection of pronunciation variants, here uploaded from a text file rules.nrul. In this rule file, simple replacement rules define which variants are possible for a word or a sequence of segments in the canonical transcription. For the word Märel [mE.R@l] the ruleset here assumes nine phonetic variants. Note that for the rule set SAMPA has to be used instead of IPA.
-m,E:,R,@,l->-A,m,z,@,l-
-m,E:,R,@,l->-k,u@,p-
-m,E:,R,@,l->-f,u,l-
-m,E:,R,@,l->-f,U,l-
-m,E:,R,@,l->-f,i,l,S,@,-
-m,E:,R,@,l->-S,m,u@,b,@,l-
-m,E:,R,@,l->-S,m,u,P6,b,@,l-
-m,E:,R,@,l->-S,p,R,P3I,f-
-m,E:,R,@,l->-S,p,A,t,s-
After the successful run of the MAUSwebservices, the emuDB now contains information about the potential variants in the audio recordings. The following visualisation shows the waveform for one audio file aligned with the phonetic segments.

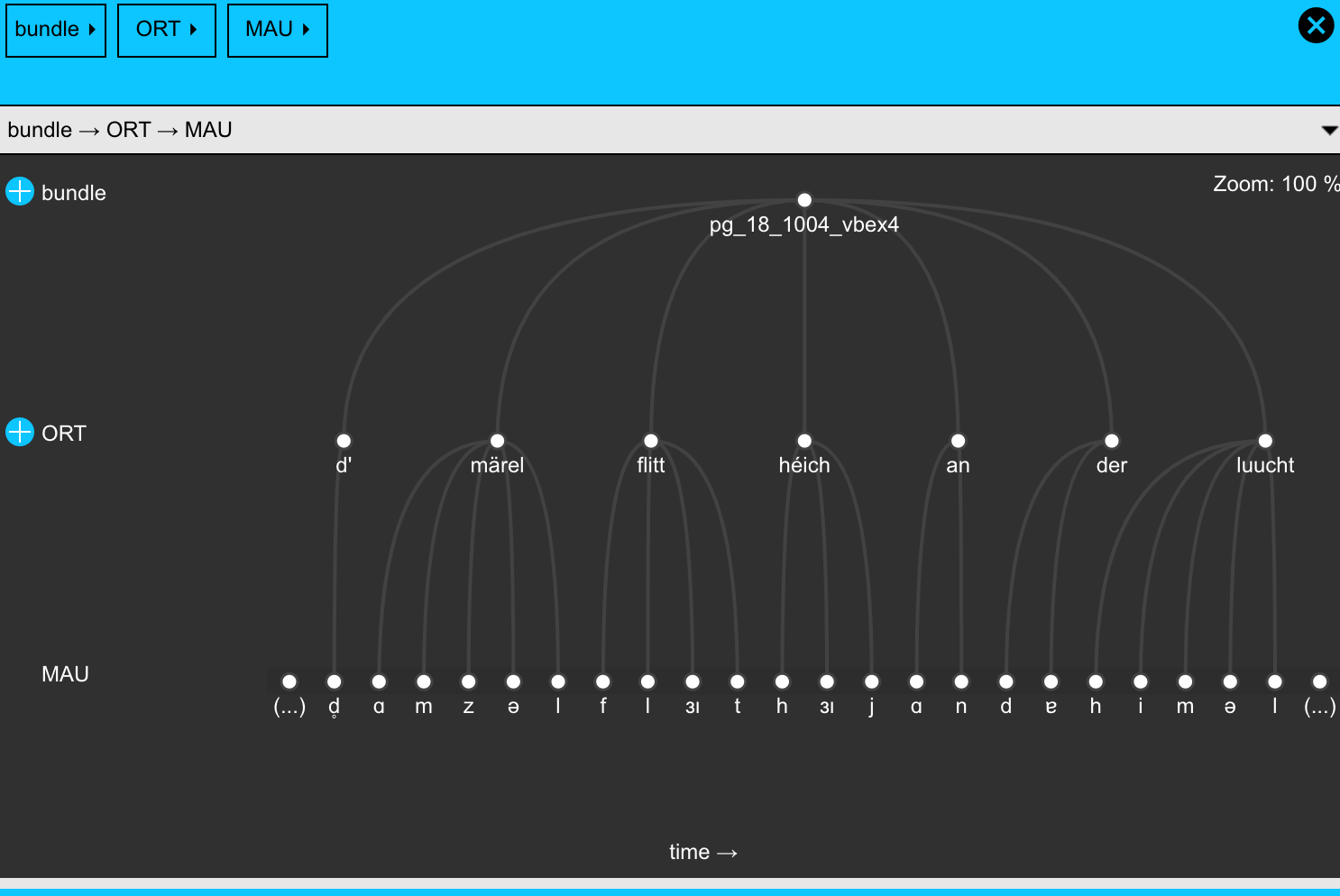
The following example shows the hierarchical view on the annotation structure. Note that here the orthographical word ‚märel‘ is associated with the phonetic segments [ɑ m z ə l], meaning that in the alignment process the acoustic structure of this word has been classified as a variant.
Some R code is needed to obtain an overview of the distribution of the detected variants in the dataset. The emuDB database is queried for the word märel on the ORT tier and the resulting associated phonetic segments from the MAU tier are returned.
word <- "märel"
query <- paste0("[ORT== " , word, "]")
#query <- paste0("[ORT== " , word, " ^ MAU =~l ]")
sl_words <- query(db, query = query)
sl <- requery_hier(db, seglist = sl_words, level='MAU')
variants <- sl %>%
group_by(labels) %>%
mutate(labels = str_replace_all(labels, "->","")) %>%
tally(sort = T)
variants
And finally, we obtain the following list of variants and their frequencies in the dataset.
# A tibble: 9 x 2
labels n
<chr> <int>
1 mɛːʀəl 623
2 ɑmzəl 540
3 fʊl 20
4 filʃə 19
5 ful 16
6 kuəp 9
7 ʃmuəbəl 8
8 ʃpʀɜɪf 4
9 ʃpɑts 1
… and this is the desired result. 🙂
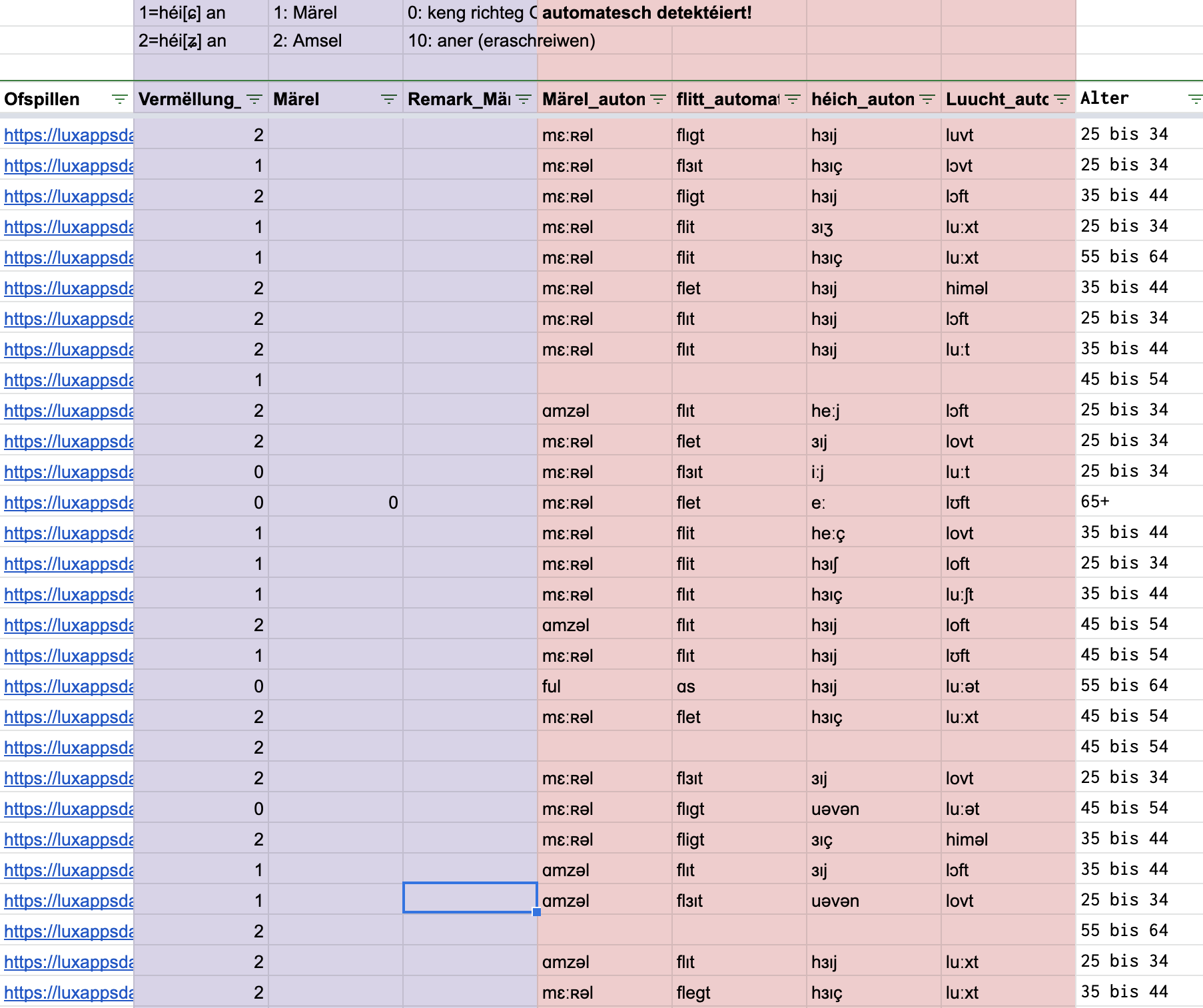
The results then can be automatically imported into the Google Sheets table, where we normally do the manual annotation of the audio data.
Further directions
The described (semi-)automatic variant detection here has some limitations: The quality of the variant detection can only be estimated when directly compared manual variant annotations. First informal evaluation indicates an approximate error rate of up to 20 %. A problem also is that there is no likelihood about the detection rate: The aligner is assigning a variant whenever it recognises a certain similarity with a possible pronunciation variant. However, having some information about the likelihood about variant assignment would help to identify false positives and false negatives. The system will assign a variant regardless of any audio input. It present, the system is working pretty much like a black box. Finally, all potential variants have to be known beforehand. For a huge database like ours, which is intended to investigate ongoing variation, it is not possible to know all variants. Some further control and evaluation steps in the recognition systems are thus necessary for future developments.
Further ideas on how to improve this kind of variant detection are always welcome.
@PeterGilles



Firwaat kréien ech är Kommentären an all dee Blödsinn op englesch. Dir schafft un der Lëtzebuerger Sprooch, dann haalt iech och drun. Ech sin a bleiwen Lëtzebuerger an si frou lëtzebuergesch ze schwetzen an ze schreiwen.