
In collaboration with the Bavarian Archive for Speech Signals, we have developed a new functionality for the automatic analysis of spoken speech data: Luxembourgish has been added to the list of languages of the BASWebServices for the automatic analysis of sound files.
It is now possible to process the phonetic segmentation of speech recordings automatically, provided an orthographic version of the spoken data is already available. Based on a neural network, the MAUS system analyses the sound file and then matches the correct phonetic signal with the corresponding word. The MAUS system also provides the necessary grapheme-to-phoneme conversion similar to our own tool. This segmentation possibility allows fundamentally new quantitative research on the phonetics of Luxembourgish, e.g. as a preprocessing step for speech recognition.
The simplest way to use MAUS for Luxembourgish is by uploading a sound file and a corresponding text file containing the written text via the web interface.
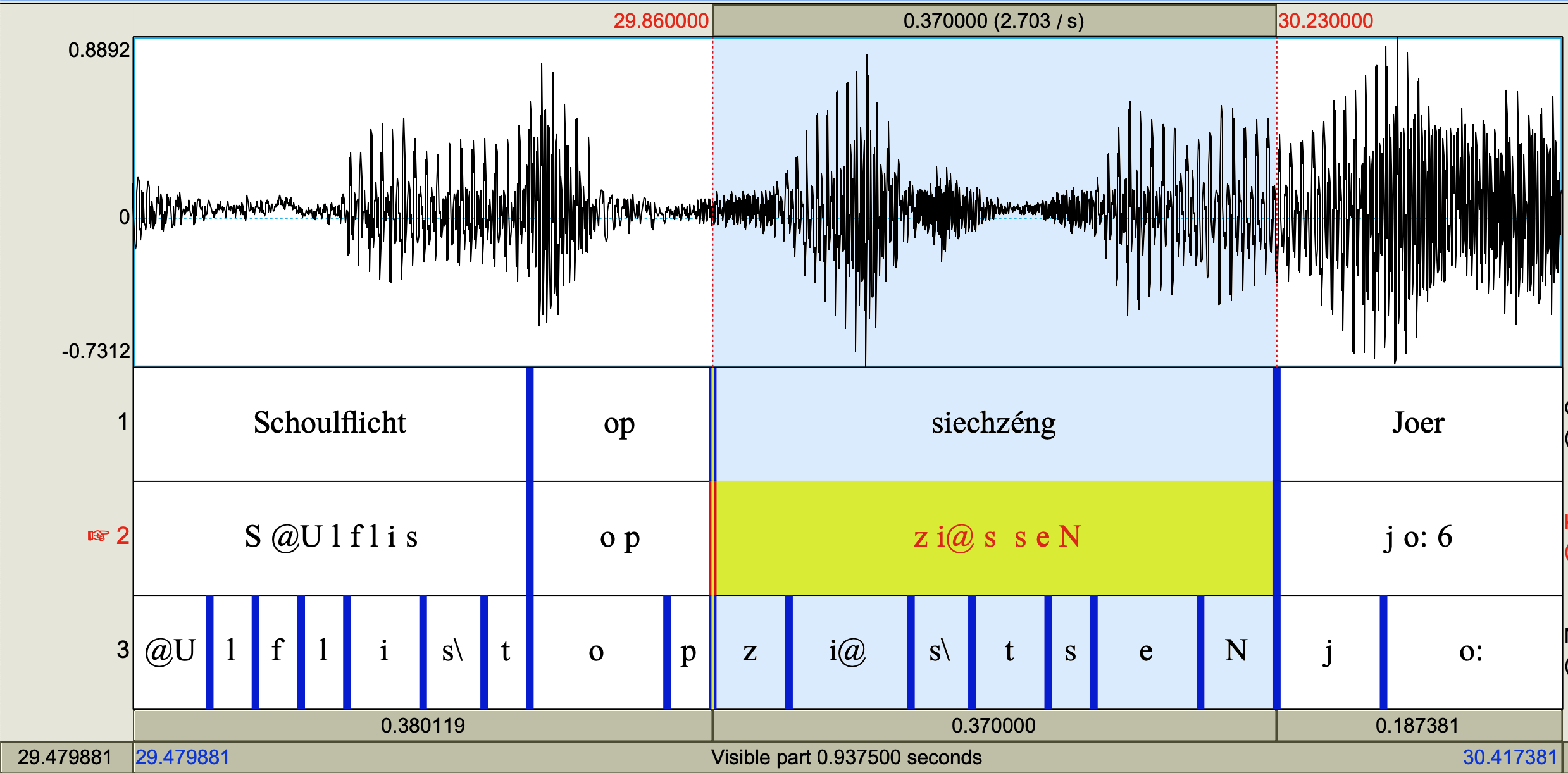
The segmentation results are delivered in various format, e.g. as a Praat TextGrid or a emuR database. The following illustration shows the segmentation in a Praat TextGrid, containing the wave form as well as the segmentation into orthographic words, phonetically transcribed words and – on the lowest tier – individual phonetic segments.
Using the segmentation tool is free of charge and open to everyone. Entry points are available via a web interface, an API or even as dedicated commands in emuR. Provided the sound files are managed as an emuR database, the following R one-liner will add phonetic transcription and word boundaries to the entire dataset:
runBASwebservice_maus(dbhandle, # select the emu database
canoAttributeDefinitionName="KAN", # indicate the layer with the orthographical / canonical transcriptions
language="ltz-LU", # select lanuage
mausAttributeDefinitionName="MAU2") # select segmentation mode
I used the segmentation pipeline (e.g. for my recent paper at ICPhS) to analyse the merger of the consonants [ɕ] and [ʃ] based on data from more than 2.000 speakers in our Schnëssen database.
Special thanks to Florian Schiel and his team at the IPS in Munich.



