After I saw the amazing maps on the languages used on Twitter for the cities of New York, London and the world, I started wondering how the data resources provided freely and publicly by the millions of Twitter users might by used for linguistic analysis. I started my own little TweetCollection campaign in the first place to produce a map of Europe to visualize the different languages and to identify regions of multilingualism.
The following map is based on 1.7 millions of tweets collected during the last month within the shown bounding box of Europe and sent off by Twitter users who shared their geographic location. Stored in a MySQL database and using R (ggmap, ggplot2) for the cartography, individual points each represent a tweet and its color represent the language. Language detection for a short text of maximum 140 characters is not an easy task and I am relying here on the information provided by Twitter’s own language detection algorithm (‚lang‚ attribute introduced in March ’13). As one would expect, the coloring of the map is depicting rather clearly the distribution of the big European languages. The map also visualizes Twitter activity in general: The most active regions are UK, The Netherlands, France, Italy and Spain, while Germany and many eastern countries show much less activity.
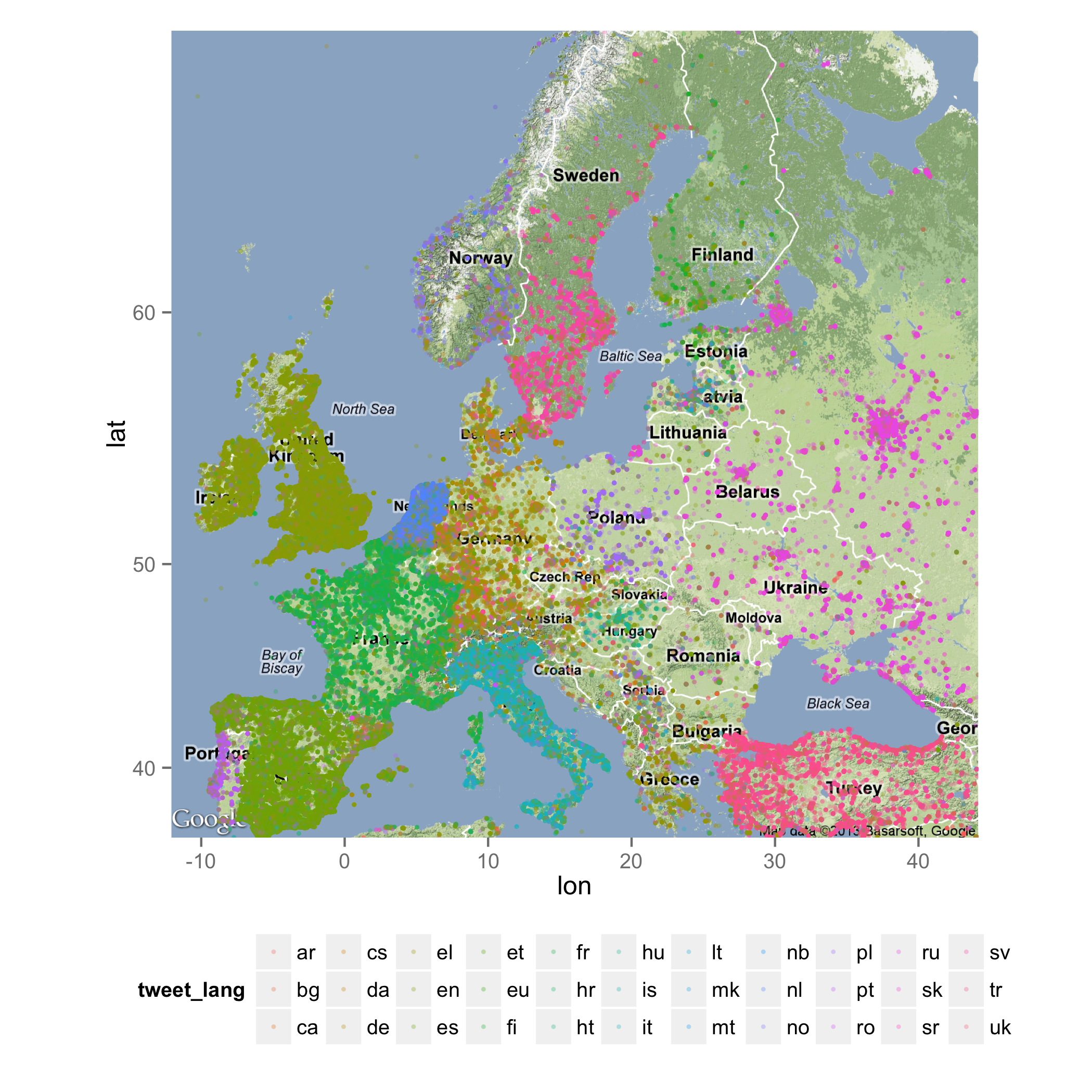
Languages used on Twitter (click to enlarge)
Maybe more interesting is the visualization of smaller regions and urban areas. The following map show the extensive mixture of Spanish and Catalan in the Barcelona region.

Spanish and Catalan tweets in the Barcelona urban area
This map shows Paris in facet wrap, illustrating, next to the dominance of French, the high amount of tweets in Czech, Spanish and Italian – most probably due to tourism (other languages are omitted here for the sake of illustration).
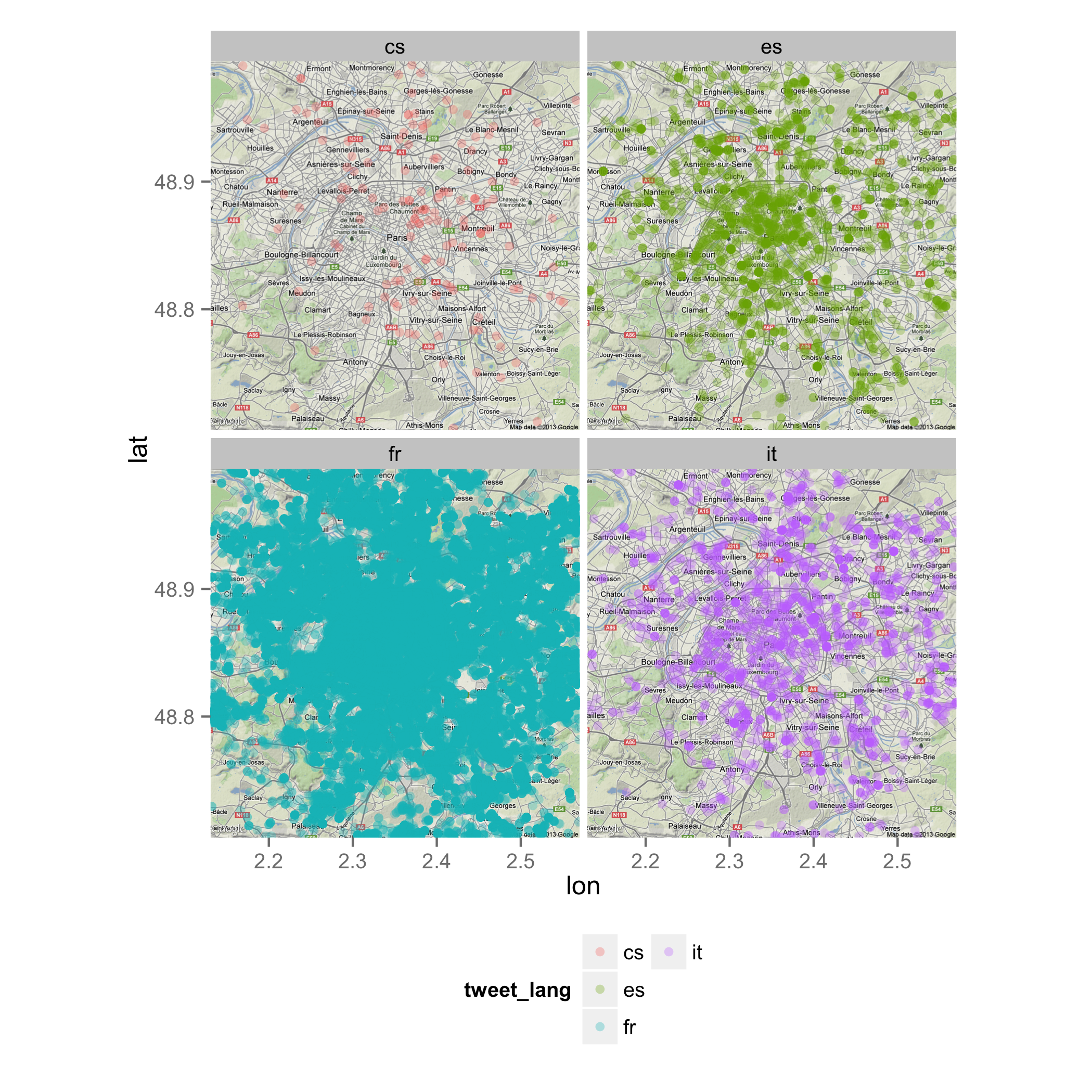
Czech, Spanish, French and Italian tweets in Paris
The distribution of French, Dutch and English in the official bilingual city of Brussels is the topic of the next map. French (green) and English (red) are concentrated in the inner city, intermingled and surrounded by tweets in Dutch (blue).

Languages on Twitter in the Brussels area
The results from these still rather small-scale analyses cannot be taken as the definitive or authoritative representation of multilingual regions, of course. A lot of technical and conceptual issues have to be taken into account (e.g, the social group using Twitter, the reliability of the language detection algorithm, the impact of tourism etc.). Nevertheless, the millions, if not billions of language bits in the Twitter universe are waiting for further linguistic analysis.
Further interesting investigations on Twitter




2 Kommentare