![]() LuxASR 2 is the follow-up project of LuxASR (2022-2024) and is financed by the Chambre des Députés, Luxembourg for four years (PI: Peter Gilles). The focus of this project is the development, evaluation and improvement of automatic speech recognition and machine translation of the Luxembourgish language.
LuxASR 2 is the follow-up project of LuxASR (2022-2024) and is financed by the Chambre des Députés, Luxembourg for four years (PI: Peter Gilles). The focus of this project is the development, evaluation and improvement of automatic speech recognition and machine translation of the Luxembourgish language.
Workpackages
- Improvement of the LuxASR system
- Speaker identification
- Real time ASR
- Machine Translation for Luxembourgish (LuxMT)
LuxMT: Multilingual Translation for the Chambre des Députés
Try LuxMTWe introduce LuxMT, the machine translation (MT) component of the Lux-ASR pipeline, automatically translating Luxembourgish to French, German, English, and Portuguese. The project is funded by and developed in collaboration with the Chambre des Députés. The ultimate goal is to develop a pipeline to automatically transcribe, diarise, and translate Luxembourgish parliamentary debates to provide multilingual subtitles in real-time during live-streaming. This service would render the debates and Luxembourgish political discourse more accessible to the Grand Duchy’s multilingual population.
Challenges of Developing an MT System for Luxembourgish
Developing an MT system requires vast amounts of data. These data take the form of parallel corpora, i.e., source texts and their translations. In the case of Luxembourgish, these data are rare as Luxembourgish was, up until recently, mostly confined to the spoken domain (Horner & Weber, 2016). In addition, this lack of data does not only affect the training of MT models, but it is also the source for many tools for MT development to be incompatible with Luxembourgish.
Furthermore, AI models require a hyperscale of resources to train from scratch. For this reason, our approach is to identify current best-performing models and fine-tune them for our use case.
The project is in constant development. Below are the general steps we take. For a more detailed documentation of how LuxMT (v1) was developed, see Rehlinger (2026).
Benchmark
To identify the best-performing base model and verify the fine-tuning improvements, we need a robust evaluation procedure. We compiled a benchmark using Luci, a multilingual tourist magazine about Luxembourg written in Luxembourgish, French, German, and English, and constructed an ensemble of automatic MT evaluation metrics to score models‘ performance on the benchmark. At this time, the Luci benchmark consists of 500 segment pairs per language pair (LB→FR, LB→EN, LB→DE). We are also developing a test-suite to assess models in a fine-grained manner across a wide range of linguistic phenomena.
Base Model
After assessing various popular local LLMs, we found that Google’s Gemma 3 is currently the most promising model and serves as the base model for further fine-tuning (Team et al., 2025).
Training Data and Filtering
The main sources of our data are from LuxAlign (a parallel corpus of RTL news articles) and the Chambre des Députés. RTL news articles are written in Luxembourgish, French, and English, and we augment the Luxembourgish transcripts by the Chambre des Députés using larger MT models to translate the data into French and English.
We filter the data with LuxEmbedder, Luxembourgish sentence embeddings, to remove low-equivalence segment pairs, as the RTL articles are not 1-to-1 translations.
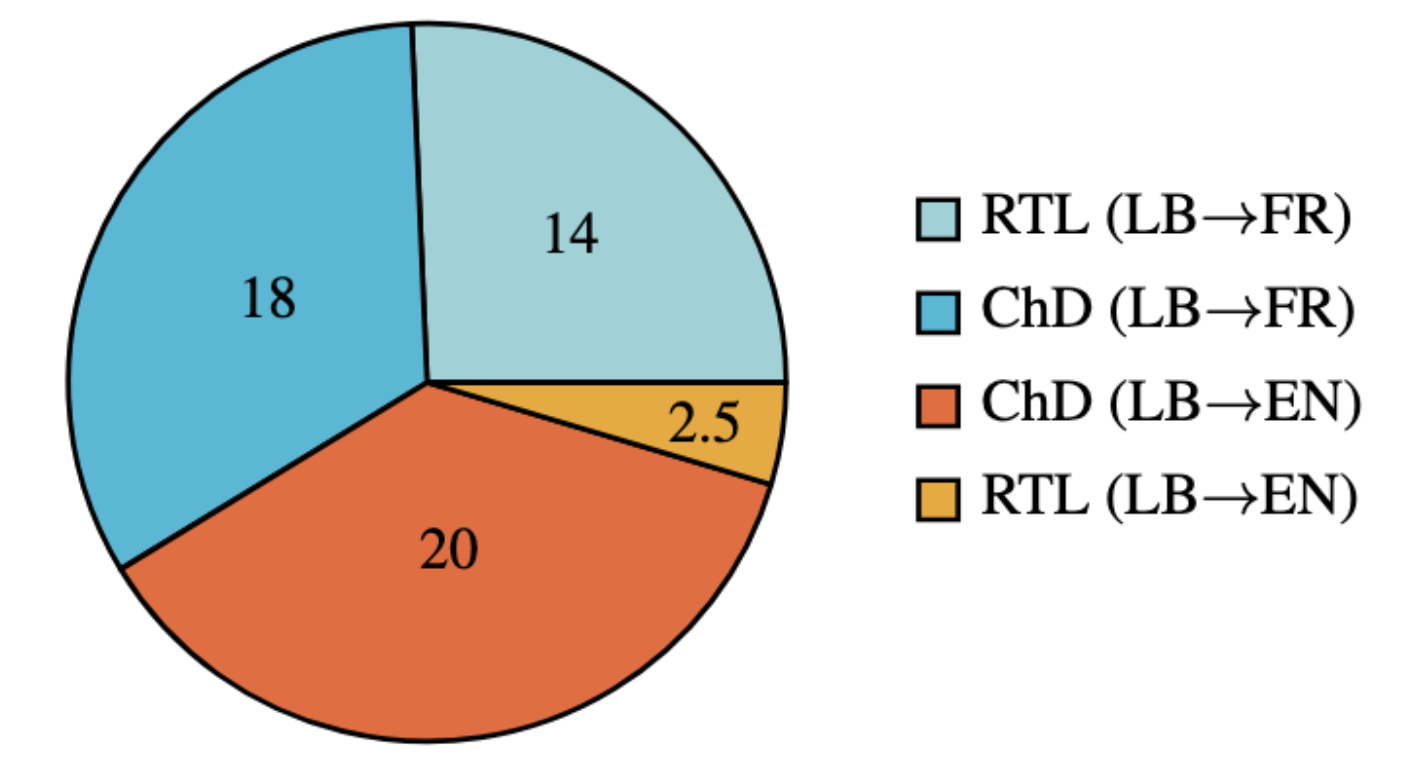
Figure 1: Training data of LuxMT v1.
LB→FR total: 32k segment pairs;
LB→EN total: 22.5k segment pairs;
Grand total: 54.5k
Fine-tuning
We fine-tuned the model using the Unsloth suite. The model was fine-tuned for one epoch with a learning rate of 2e-5.
Evaluation
We evaluated LuxMT on the Luci benchmark and found substantial improvements of LuxMT over the Gemma 3 baseline for translating Luxembourgish to French and English. Interestingly, we also found substantial improvements for translating Luxembourgish to German, even though our training data did not include any German.
BERTScore |
BLEURT-20 |
xCOMETXL |
|
LB→FR |
+0.2 |
+1.3 |
+1.9 |
LB→EN |
+0.8 |
+0.9 |
+1.2 |
LB→DE |
+0.2 |
+0.2 |
+0.6 |
Table 1: Performance gains of LuxMT over the Gemma 3 baseline on the Luci benchmark (N = 500 per language pair).
Future Work
In the future, we plan to:
- explore an estimated translation difficulty filtering for the training data (Proietti et al., 2025);
- fine-tune the TranslateGemma model and European models (Finkelstein et al., 2026);
- fine-tune the model to translate into Luxembourgish;
- implement automatic post-editing procedures to boost translation performance.
References
- Finkelstein, M., Caswell, I., Domhan, T., Peter, J. T., Juraska, J., Riley, P., … & Vilar, D. (2026). TranslateGemma Technical Report. arXiv preprint arXiv:2601.09012.
- Horner, K., & Weber, J. J. (2016). The language situation in Luxembourg. In Language planning in Europe (pp. 180-240). Routledge.
- Proietti, L., Perrella, S., Zouhar, V., Navigli, R., & Kocmi, T. (2025). Estimating machine translation difficulty. Preprint.
- Rehlinger, N. (2026). LuxMT Technical Report. arXiv preprint arXiv:2602.15506
- Team, G., Kamath, A., Ferret, J., Pathak, S., Vieillard, N., Merhej, R., … & Iqbal, S. (2025). Gemma 3 technical report. arXiv preprint arXiv:2503.19786.