
We are happy to announce the release of the first forced alignment model for Luxembourgish, now openly available on GitHub:
👉 https://github.com/PeterGilles/Luxembourgish_in_Montreal_Forced_Aligner
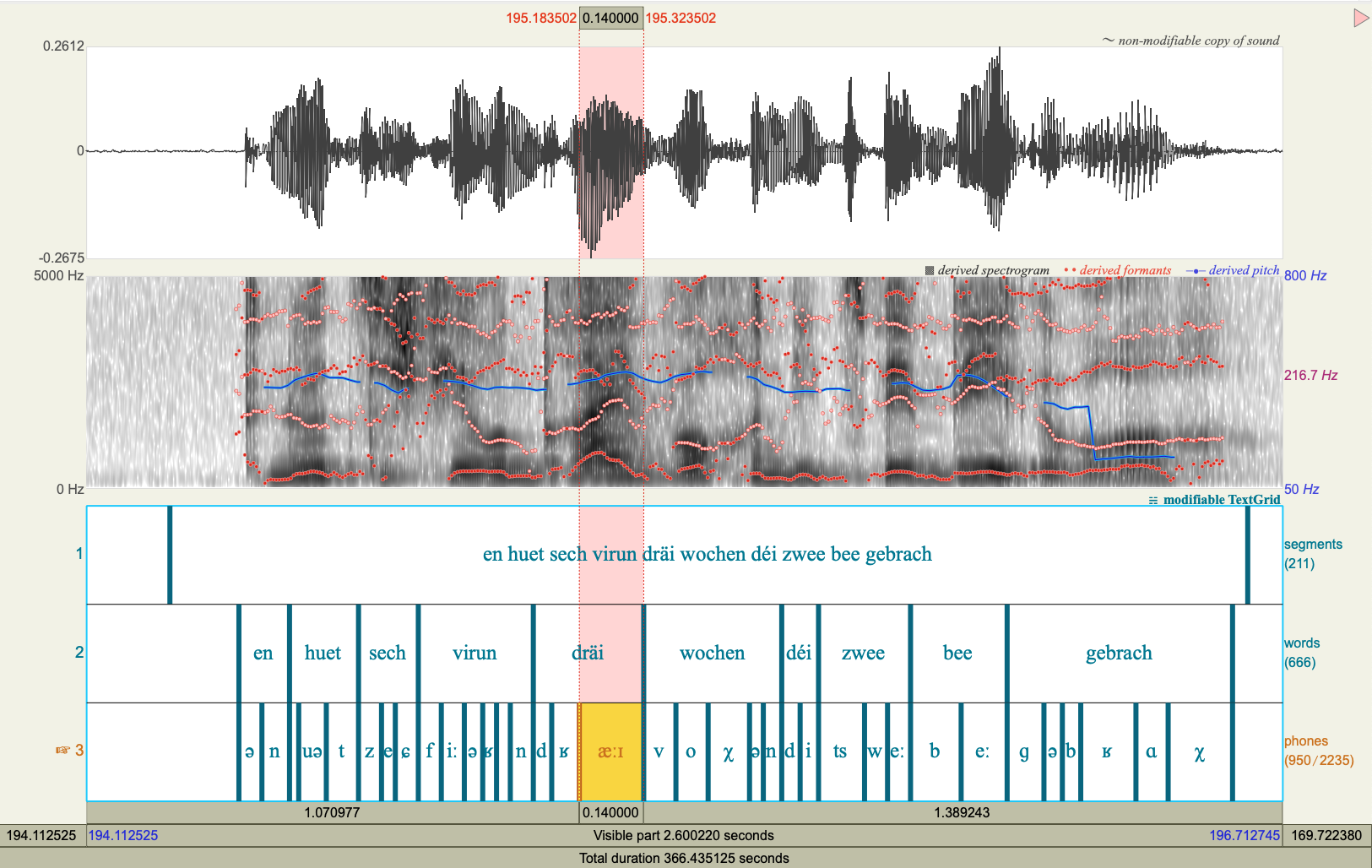
Forced alignment is a key technology in speech and corpus linguistics, allowing researchers to automatically align audio recordings with their transcriptions at the level of utterances, words and phones.
About the model
The Luxembourgish forced aligner was trained on 50 hours of transcribed speech, resulting in a model that can align speech data with a high degree of accuracy. The aligner produces Praat TextGrid files, making it immediately usable for phonetic and linguistic analysis workflows.
This aligner will significantly facilitate linguistic research on Luxembourgish, as it enables researchers to process and align large amounts of audio data efficiently and reliably—a task that would otherwise require extensive manual annotation.
Integration with LuxASR
The aligner is designed to work seamlessly with existing tools: its input can be generated directly from the text output of our automatic speech recognition system, LuxASR. This makes it possible to move from raw audio to aligned linguistic data in a streamlined pipeline.
By making this tool publicly available, we hope to support ongoing and future research on Luxembourgish and encourage further development of language technologies for under-resourced languages.




