In einem soeben erschienen Artikel in Science* unternimmt ein Autorenkollektiv aus Computerwissenschaftlern (Jean-Baptist Michel, Erez Lieberman Aiden), Mathematikern, Psychologen, Systembiologen und Linguisten (i.e. Steven Pinker) den Versuch, einen neuen Zweig der quantitativen Erforschung von Kultur zu begründen, den sie Culturomics nennen. Ziel ist es, kulturelle Veränderung und Entwicklung über das Vorkommen von Begriffen, Konzepten, Wörtern, wie sie sich in Büchern präsentieren, über die Zeit hinweg zu quantifizieren. Die für solche Untersuchungen notwendige Datenmenge kommt von Google Books. Lassen sich mit dieser Datenmenge auch luxemburgistische Fragestellungen angehen?
Das Google Book-Korpus besteht aus eingescannten und text-aufbereiteten Daten von 5,4 Millionen Büchern, in denen sich über 500 Milliarden (!) laufende Wörter tummeln (darunter 39 Mrd für Deutsch, 45 Mrd für Französisch). Diese Datenmenge ist so enorm, dass sich für viele Begriffe statistisch verlässlich Aussagen über ihre Relevanz in verschiedenen zeitlichen Epochen machen lassen. Der Grundgedanke der Analysemethode basiert auf einer Darstellung der Häufigkeit von Wörtern oder Phrasen pro Jahr. Unter der simplistischen (?) Annahme, dass häufige Nennung mit kultureller Wichtigkeit gleichzusetzen ist – über kulturell Bewegendes wird häufig gesprochen, mithin auch geschrieben und publiziert -, können Trends in der kulturellen Entwicklung visualisiert werden. So zeigen die Autoren u.a., wie sich Häufigkeiten etwa für Speisen über die Zeit verändern. Das folgende Beispiel illustriert für das Englische die Häufigkeiten einzelner Speisen. Während sich steaks konstant zunehmender Beliebtheit erfreuen, lassen sich für ice cream zwei Beliebtheitshöhepunkte feststellen (1950 und 2000), die zudem an die Häufigkeit von steaks gekoppelt zu sein scheinen. pasta und pizza verlaufen erwartungsgemäß seit den 1970er Jahren parallel. sushi tritt ab 1990 in den englischen Wortschatz.
Häufigkeiten von steak,sausage,ice cream,hamburger,pizza,pasta,sushi in englischsprachigen Büchern (1800-2000)
Der erwähnte Aufsatz enthält zahlreiche Beispiele, wie diese neue Methode – wenn überhaupt von neu gesprochen werden kann, denn eigentlich ist lediglich die Verfügbarkeit der riesigen Datenmenge das wirklich Neue – angewendet werden kann, etwa zur Bestimmung der ‚Berühmtheit‘ von Personen und Ereignissen, das Aufkommen, die Stabilität und Wiederverschwinden von Konzepten und Dingen etc.
Selbstredend stellt diese Datenmenge eine unschätzbare Fundgrube für Sprachwissenschaftler dar, kann doch die zeitliche Entwicklung von Wörtern und grammatischen Konstruktionen in einer sehr großen Datenbasis herausgearbeitet werden. Für das Englische zeigen die Autoren, wie sich Vergangenheitsformen starker Verben entwickeln (z.B. learned vs. learnt). Eine für alle zugängliche Internetapplikation der Google Labs, der Books Ngram Viewer erstellt eine Graphik für beliebige Wörter oder Phrase einer Sprache (Englisch, Deutsch, Französisch, Russisch, Spanisch, Chinesisch) – addictive, wie die Macher der culturomics-Seite lapidar feststellen.
Im Folgenden werden ein paar Beispiele vorgestellt, wie das Verfahren für lexikalische Fragestellungen angewendet werden kann. Gleichzeitig sei auf die Einschränkungen und Gefahren hingewiesen: Der Books Ngram Viewer sucht lediglich nach Zeichenketten in beliebigen Büchern: Polysemie oder Textsortenunterschiede werden nicht berücksichtigt. Relativ zuverlässig scheint mit das Verfahren für die Beschreibung der zeitlichen Entwicklung von hochfrequenten Substantiven und Eigennamen zu sein. Sehr schön zeigt folgende Grafik etwa die Entwicklung der Bezeichnung für ‚Radioempfänger‘ seit den 1920er Jahren. Erkennbar ist, dass nach der Einführung der Rundfunktechnik gleich fünf Bezeichnungen aufkamen: Radioapparat, Rundfunkgerät, Rundfunkempfänger, Radiogerät und Radioempfänger. Während die letzten beiden sich bis in den 1940er Jahre hinein nur langsam verbreiten, erreichen die Zusammensetzungen mit Rundfunk- schnell sehr hohe Häufigkeiten: Der Rundfunkempfänger ist sicherlich ein Wort des 2. Weltkrieges, das seinen hohen Gipfel in den 1940er Jahren erreicht und dessen Gebrauch danach massiv zurückgegangen ist; ein ähnliches Schicksal ist dem Rundfunkgerät beschieden. Der Radioapparat hingegen nahm schon in den 1920er Jahren Fahrt auf und erreicht seinen Verwendungsgipfel in den 1950er Jahren. Erkennbar ist auch, dass das Transistorradio um 1970 und der Radiowecker seit 1980 als neue Lexeme in den Wortschatz des Deutschen kamen.
Entwicklung der verschiedenen Bezeichnungen für 'Radioempfänger'
Nützlich für die Luxemburgistik?
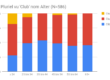
Interessant ist die Entwicklung der Schreibung des Landes- und Sprachnamens in deutsch-, französisch- und englischsprachigen Publikationen. Während Lëtzebuerg und davon neuer abgeleitet Lëtzebuergesch die älteren Formen darstellen, sind die Varianten mit -x- neueren Datums; zur Herleitung dieser komplexen Wortgeschichte vgl. den Aufsatz von Cristian Kollmann**. In deutschsprachigen Büchern ist Luxemburg bis ca. 1910 relativ selten und wird danach schnell mehr verwendet. Die Gipfel im 19. Jh. liegen um 1830 (Wiener Kongress, Londoner Verträge) und 1870 (Schleifung der Festung).
Luxemburg, Luxembourg in deutschsprachigen Büchern (1800-2000)
In Publikationen des 18. und 19. Jh. begegnen auch die Varianten Lützelburg, Lützenburg sowie Lützemburg. Die ersten beiden tauchen im Korpus insgesamt relativ selten auf, Lützemburg gar nicht. Auffällig ist, dass Lützelburg (caveat: hier liegt Polysemie vor, denn es gibt auch weitere Ortsnamen, z.B. in Frankreich) bis ca. 1880 noch vertreten ist und danach stark abnimmt, just zu dem Zeitpunkt, an dem die Konkurrenzform Luxemburg beginnt zuzunehmen.
Lützenburg, Lützelburg, Lützemburg in deutschsprachigen Büchern (1800-2000)
In französischsprachigen Publikationen ist Luxembourg bereits 1820 auf einem Häufigkeitsniveau zu finden, das bis 1960 ungefähr gleich hoch bleibt.
Luxemburg, Luxembourg in französischsprachigen Büchern (1800-2000)
Eine kuriose Entwicklung findet sich in den englischsprachigen Publikationen. Auch hier dominiert die aus dem Französischen übernommene Schreibung Luxembourg, die allerdings von 1800 bis 1940 immer in starker Konkurrenz zur deutschen Schreibung Luxemburg steht. Von diesem Zeitpunkt an kommt es dann aber zu starker Divergenz der Häufigkeitswerte der beiden Varianten. Ursache für diese Entwicklung dürfte in der Nazi-Herrschaft in Deutschland liegen. Es scheint, dass nach 1940 in englischsprachigen Büchern die an das Deutsche erinnernde Form Luxemburg diskreditiert war (die nicht wenigen Vorkommen für Rosa Luxemburg müssen davon noch abgezogen werden) und durch das französische Luxembourg ersetzt wurde.
Luxemburg, Luxembourg, Rosa Luxemburg in englischsprachigen Büchern (1800-2000)
Als Adjektiv wird luxemburgisch ab ca. 1970 verwendet und nimmt schnell an Relevanz zu. Als Sprachname hingegen mit Großschreibung, Luxemburgisch, kommt der Begriff erst um 1980 auf. Dies dürfte kein Zufall sein, wurde doch um diese Zeit im Sprachengesetz (1984) Luxemburgisch als Nationalsprache festgelegt.
Luxemburgisch, luxemburgisch in deutschsprachigen Büchern (1800-2000)
Eine parallele Entwicklung zeigen die Daten der englischen Bücher: Zunahme von Luxembourgish nach 1980.
luxembourgish, Luxembourgish in englischsprachigen Büchern (1800-2000)
Eine vergleichbare Darstellung für französischsprachige Bücher erübrigt sich, da die die Bezeichnung Luxembourgeois ambig ist und sich sowohl auf den Sprachnamen als auch auf den Einwohner beziehen kann. Allerdings lassen sich die (sehr geringen) Häufigkeiten für langue luxembourgeoise und patois luxembourgeois feststellen: Erstere Bezeichnung entsteht um 1980 und nimmt ab 1990 zu.
langue luxembourgeoise und patois luxembourgeoise in französischsprachigen Büchern
A wou bleift d’Lëtzebuergescht?
Die luxemburgischen Bezeichnungen Lëtzebuerg und Lëtzebuergesch kommen nur in deutschsprachigen Büchern und dort auch nur selten vor. Dennoch ist der Zeitpunkt auffällig: Beide Bezeichnungen treten ab 1960 in Erscheinung. Dabei bleibt der Landesname auf niedrigem Niveau, während der Sprachname ab 1980 sprunghaft zunimmt.
Lëtzebuerg, lëtzebuergesch in deutschsprachigen Büchern (1800-2000)
Beim beschriebenen Verfahren handelt es sich prinzipiell um lexikologische Korpusanalysen, wie sie von empirischen Linguisten seit langer Zeit betreiben und in dieser Hinsicht auch nicht innovativ. Neu ist sicherlich die schiere Datenmenge, wie sie ein strukturiert aufgebautes und annotiertes Korpus nie erreichbar sein wird. Ob culturomics wirklich eine neue Forschungsdisziplin wird, die kulturelle Trajektorien statistisch zuverlässig erfasst und beschreibt, möchte ich jedoch zunächst bezweifeln: Kulturelle Relevanz wird nicht ausschließlich über das Vorkommen in gedruckten Büchern kodiert und transportiert, sondern manifestiert sich in zahlreichen weiteren Manifestationsformen (künstlerischen Artefakten, Zeitungen/Zeitschriften etc.), die durch Google Books-Daten (noch) nicht erfasst werden.
Mehr lesen
* Jean-Baptiste Michel*, Yuan Kui Shen, Aviva Presser Aiden, Adrian Veres, Matthew K. Gray, The Google Books Team, Joseph P. Pickett, Dale Hoiberg, Dan Clancy, Peter Norvig, Jon Orwant, Steven Pinker, Martin A. Nowak, and Erez Lieberman Aiden*. Quantitative analysis of culture using millions of digitized books. Science. Published Online Ahead of Print: 12/16/2010.
** Cristian Kollmann. Der Name Luxemburg. erscheint in Beiträge zur Namenforschung.
Weitere Artikel zu culturomics:
http://blog.veronis.fr/2010/12/google-le-plus-grand-corpus.html (Jean Véronis)
http://david-crystal.blogspot.com/2010/12/on-culturomics.html (David Crystal)
http://languagelog.ldc.upenn.edu/nll/?p=2848 (Mark Liberman)
http://chronicle.com/article/Counting-on-Google-Books/125735/ (Geoffrey Nunberg)